
目标检测(Object Detection) - YOLOv8
简介(Introduction)
BAAS使用YOLOv8训练目标检测模型, 识别角色位置, 并用于自动战斗的技能释放等操作
效果展示
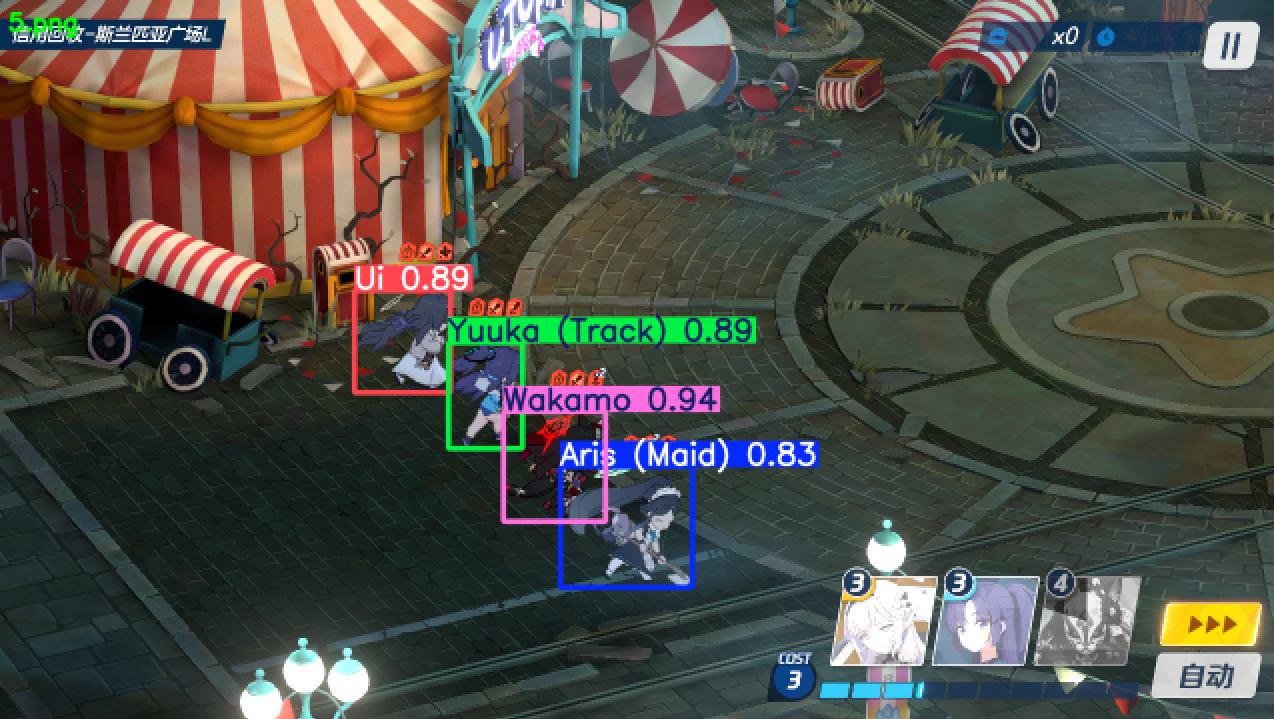
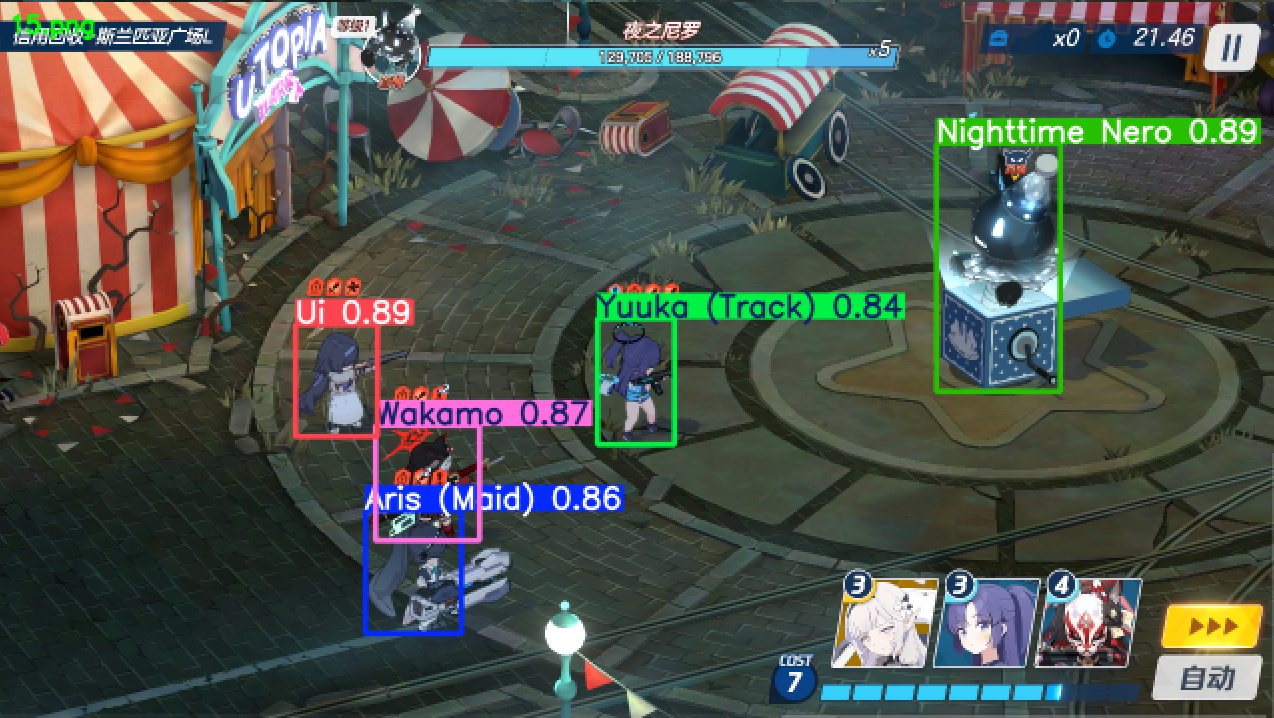

需求分析
任务类型: 分类, 检测
输入图像:
- 尺寸: 1280x720
- 色彩空间: RGB 三通道彩色图像
输出:
- 输出是一个 列表, 该列表可能包含 0 到 N 个 元素,其中 N 是图像中检测到的目标数量。 列表中的每个元素包含以下三个信息:
- 位置
- 类别
- 置信度
其他特性:
- 鲁棒性: 在不同背景, 视角, 遮挡下, 多目标并存时仍能准确分类和定位
- 实时性: 低延迟, 推理速度快
- 增量学习: 模型持续接收新数据学习, 模型可以添加新类别继续训练
数据采集
- 在
不同关卡下运行游戏, 角色随机排列 (保证背景不同并产生随机的遮挡效果) - 程序每隔一定时间进行截图并保存
- 截图的编号由
1开始自增 - 保存的图像分辨率统一为1280x720
- 筛去不含任何角色的图像
数据标注
将数据采集中的截图上传至网站cvat.ai中并进行标注, 标注者共用一个帐号
- 账号见数据标注QQ小群:
763415311
标注要求:
- 用两点矩形标注
- 矩形
紧贴四肢, 不包含头顶的血条, 包含光环, 如果角色的枪管很长,不包含枪管, 仅标注角色身体部位 - 角色被特效 / 背景部分遮挡, 需要标注
- 角色被重度遮挡, 不标注




cvat.ai使用指南
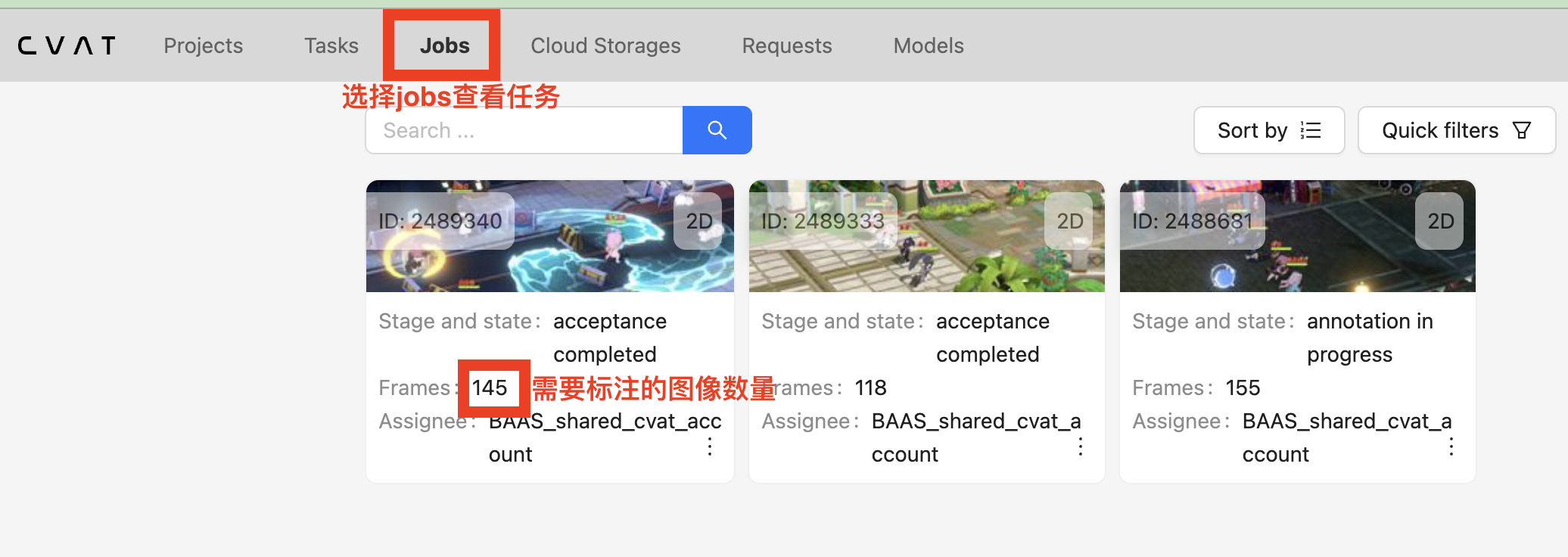
登陆账号后在
jobs中寻找被分配的标注任务点击进入以下界面开始标注
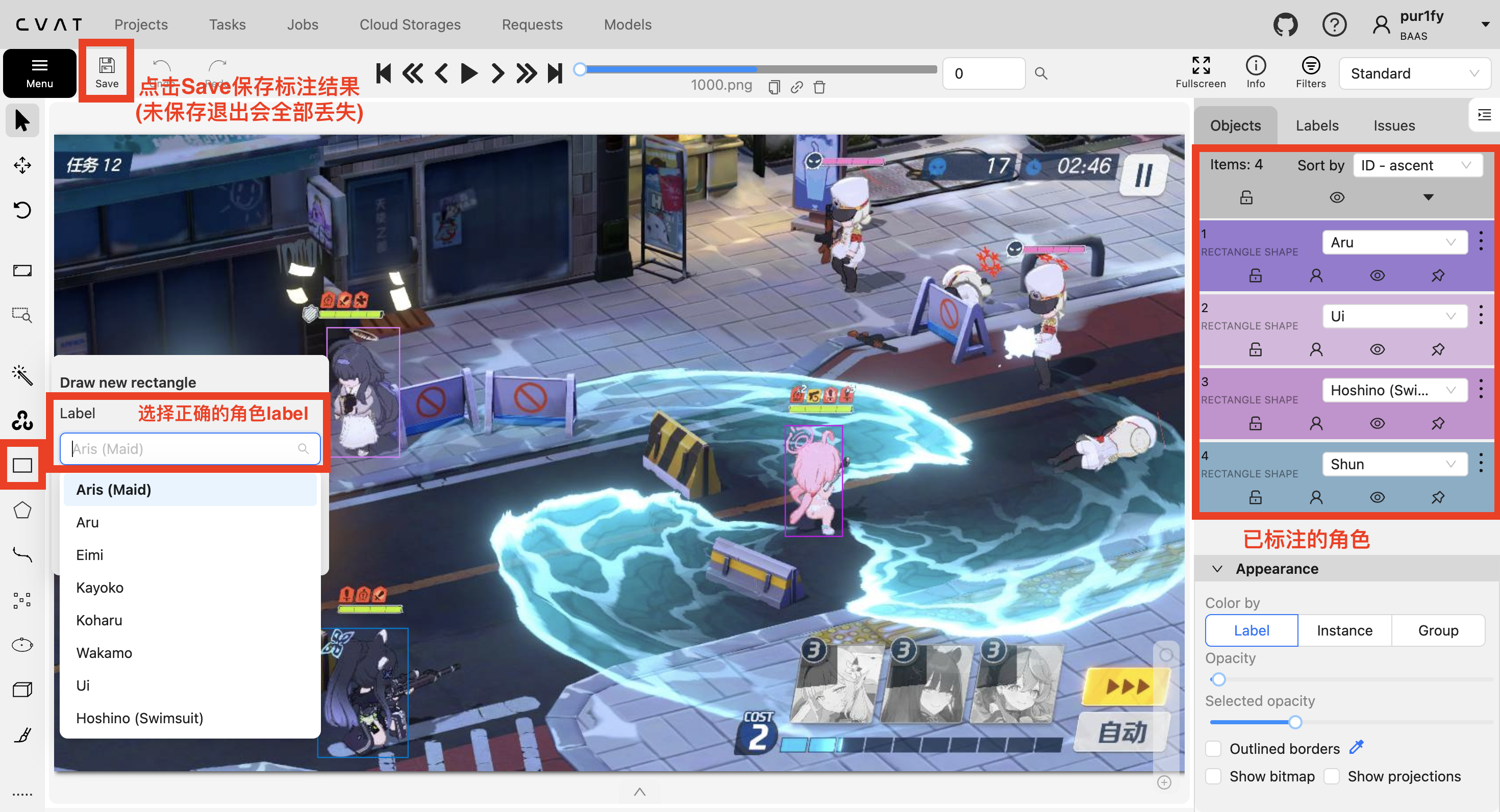
- 快捷键:
D: 上一张图片F: 下一张图片N: 两点矩形标注快捷键
推荐将一个角色标注完后再进行下一个角色的标注
数据划分
为了使模型有较好的可迁移性, 划分较大的验证集
- 所有截图在训练前按照
训练集 : 验证集6 : 4或7 : 3的比例随机划分